Одним из самых популярных способов оценки данных при размещении ставок является использование среднего значения. Но есть ли от него польза? Например мода и медиана являются более подходящей альтернативой. Для нас крайне важно разобраться в этих понятия для успешных ставок.
Какие могут быть трудности при использовании среднего значения для игроков?
Большинство букмекерских игроков для статистического расчета результатов используют среднее значение. Но много ли из них знают о недостатках среднего значения?
При ставках на футбол, на общее количество голов, многие придерживаются мнения, что среднее количество голов которые были забиты в предыдущие матчи, позволяет точно определить сколько голов будет в следующей игре. Но эффективность и верность такого подсчета под большим вопросом.
Давайте посмотрим на примере.
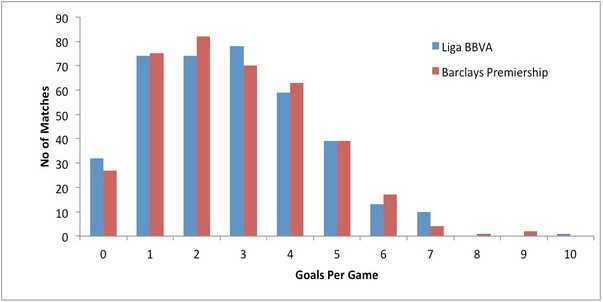
В сезон 2013/2014 Premier League и La Liga было забито среднее значение голов (на одну игру) 2.77 и 2.75 для каждой из лиг. Выходя с этих статистических данных можно придти к выводу что в La Liga чаще, чем в Premier League игры заканчиваются с результатом не превышающим 2,5 гола. Но на самом деле это не так. 48.45% игр в Premier League заканчиваются меньше, чем в 2.5 гола, а если посмотрим аналогичный показатель для La Liga то увидим что он составляет 47.3%.
На диаграмме мы можем увидеть что при одинаковом числовом распределении для Premier League , чаще достигается результат два гола/игра, а для La Liga значение уже будет три гола. Так что мы видим что среднее значение скрывает это.
Собственно возникает вопрос, а почему все именно так? Хоть среднее значение дает общее представление по ситуации, но при этом оно не учитывает формы распределения.
Средние значения опасно использовать, например, для оценки гандикапов слабых сборных (которые считаются аутсайдерами в группе) во время участия в международных футбольных турнирах. Но неужели все так плохо? При подсчете среднего количества голов забитых за одну игру можно получить большие итоговые показатели, но они могут изменится с учетом более редких довольно серьезных поражений, и это может привести к тому что игроки могут переоценить ожидаемое количество голов.
Альтернатива среднему значению это мода и медеана. Используют три набора чисел для рассмотрения двух вариантов событий, при которых среднее значение может быть неверным.
Пример. Среднего значение каждого из ряда чисел 5.
- Набор А: 4, 5, 5, 5, 6.
- Набор Б: 3, 4, 4, 4, 10.
- Набор В: 3, 4, 5, 6, 7.
Первый вариант развития событий
Хоть у этих трех наборов чисел и одинаковое среднее значение, и в сумме они дают 25 но их распределение разное.
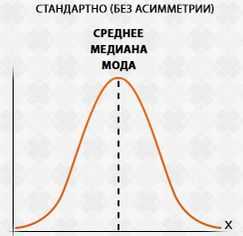
Первый ряд (А) можно отнести к симметричному распределению.
При симметричном распределении, средние значение это очень хороший вариант, когда значение переменных возникают с одинаковой частотой в начале и в конце данного набора чисел. Тут среднее значение можно увидеть посередине набора.
Ряд Б содержит четыре числа ниже среднего значения, тут только одно число превышает среднее значение. Д этом случае возникают несимметричное распределение.
Если использовать большой набор данных, то игроки могут проверить эффективность среднего значения с помощью других показателей — медианы и моды.
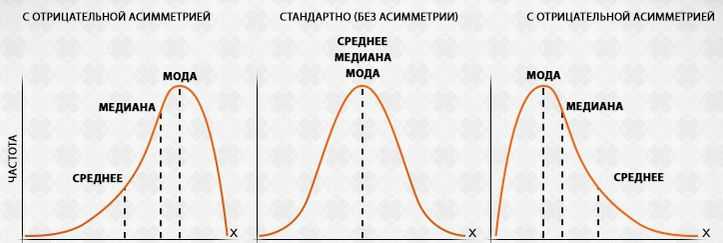
Медиана — это значение, занимающее среднее положение в распределении при группировке в возрастающим или убывающим порядке. В наших последовательностях (А и Б рядах) это 5 и 4 соответственно. Мода — это наиболее часто встречающее значение — 5 и 4 соответственно.
При симметричном распределении среднее арифметическое, медиана и мода должны быть одинаковыми. Различные между двумя последними значениями и средним арифметическим в ряде Б указывает на то, что это несимметричное распределение. Получается, что среднее значение не самый лучший вариант в данном случае.
Второй вариант развития событий.
Два ряда чисел, с различным разбросом значений, могут быть симметрично распределены. Ряд В симметрично распределен, как и ряд А, из-за того, что числа в начале или в конце ряда равномерно уменьшаются или повышаются, с учетом среднего значения.
Поскольку мы в итоге получаем среднее значение 5, то оно больше подходит для ряда А, поскольку этот ряд содержит больше чисел которые близкие к среднему арифметическому числу. Тут основная разница между двумя рядами состоит в разбросе значений в группе. Поэтому важно определить разброс значений.
С этой целью игроки могут рассчитать размах и среднеквадратическое отклонение. Размах — разница между максимальным и минимальным значениями, можно очень легко рассчитать. Но с другой стороны, вычисление среднеквадратического отклонения это уже более сложная задача.
Величина размаха для наборов А и В составляет 2 и 4, среднеквадратическое отклонение — 0.71 и 1.58 соответственно. Обе величины больше на ряда В, это еще один показатель того что в последней группе наблюдается более существенное различие.
Выводы
Если вы разберетесь в недостатках метода с использованием среднего значения (несимметричные распределения и различный разброс значений), то вы сможете принимать более взвешенные решения относительно его применения при прогнозировании результатов. Тщательный анализ применимости среднего значения не был проведен, однако представленных данных должно хватить для того что бы предостеречь и напомнить о других показателях.